Predicting stroke (III): Clustering
Last part of the series Predicting stroke.
Description
So far, all the analyses that have been performed were aimed at solving a supervised learning problem, namely, classifying individuals who suffer, or not, stroke. At all times it is known to which category each one belongs, and therefore it is possible to assess the accuracy in the classification.
However, it is also possible to pose another type of problem. Without taking into consideration the class to which each subject belongs, can we form from the predictor variables two groups that correspond to the profile of individuals who suffer stroke and the profile of those who do not suffer stroke?
That kind of question can be answered using clustering techniques such us K-means
Results
After performing a k-means analysis assuming $k=2$ we get the following results
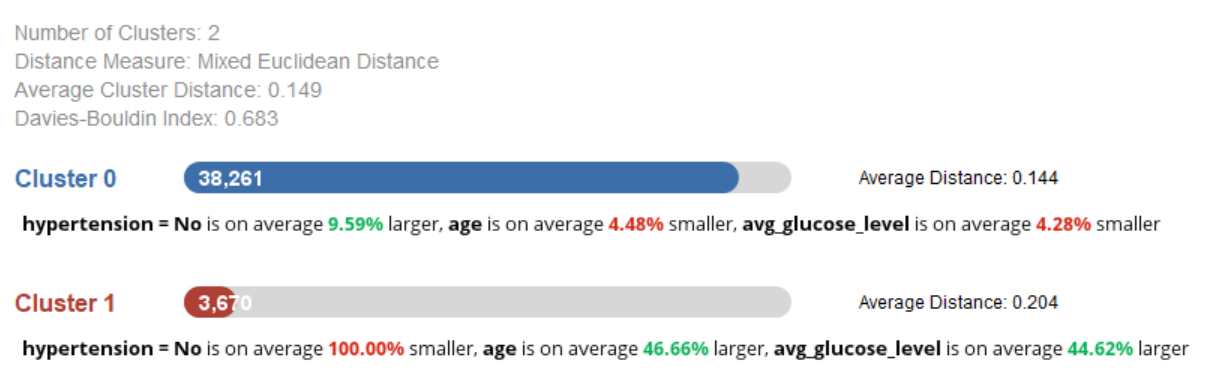
The characteristics of the of the clusters generated are pretty similar to what we could expect theoretically. The vast majority of subjects belong to cluster 0, which we can call low-risk, and a smaller percentage is categorized as high-risk. It can be observed in the characteristics of cluster 1 that both age and glucose level are more than 40% higher, which is consistent with what is known (Boehme et al, 2017). In addition, among these subjects, hypertension is clearly higher, although since it is a categorical variable, the interpretation is more useful in terms of proportions.
If you want to know more, check the full report. The Rapidminer file cab found clicking on this link.
References
Boehme, A. K., Esenwa, C., y Elkind, M. S. (2017). Stroke risk factors, genetics, and prevention. Circulation research, 120(3), 472-495.