SQL and Python to explore IMDb movies
Description
Knowing SQL is a must if you want to become a data scientist. From what I’ve seen in LinkedIn data-related job posts, the majority of employers are looking for people skilled in the use of SQL. I started learning SQL in 2020, but up to date I’ve never completed a project involving only SQL.
I’m changing that now. In the present project I’ve created a database from the imdb datasets using SQLite. I’ve written some queries to answer some basic but nonetheless interesting questions about cinema (e.g. which decade of the 20th century has movies with better ratings on average?) and finally I’ve translated some of this results into plots with the help of python and seaborn. To make things more challenging for me, I’ve developed the first part of the project (gathering the data and creating the database) using only the command line interface in a ubuntu “virtual machine” (the Windows Subsytem for Linux to be precise), without relying on GUIs.
Here is the executive report I made showing all the project stages.
An example: Stanley Kubrick’s filmography
To get the films and ratings I had to use all 5 tables contained in the database (more info about each table in the imdb link):
SELECT title, titleType, startYear AS year, averageRating as rating
FROM crew
INNER JOIN names ON crew.directors = names.nconst
INNER JOIN ratings ON crew.tconst = ratings.tconst
INNER JOIN akas ON ratings.tconst = akas.titleId
LEFT JOIN basics ON akas.titleId = basics.tconst -- left join to avoid losing data
WHERE primaryName = 'Stanley Kubrick' AND isOriginalTitle = 1
ORDER BY year ASC;
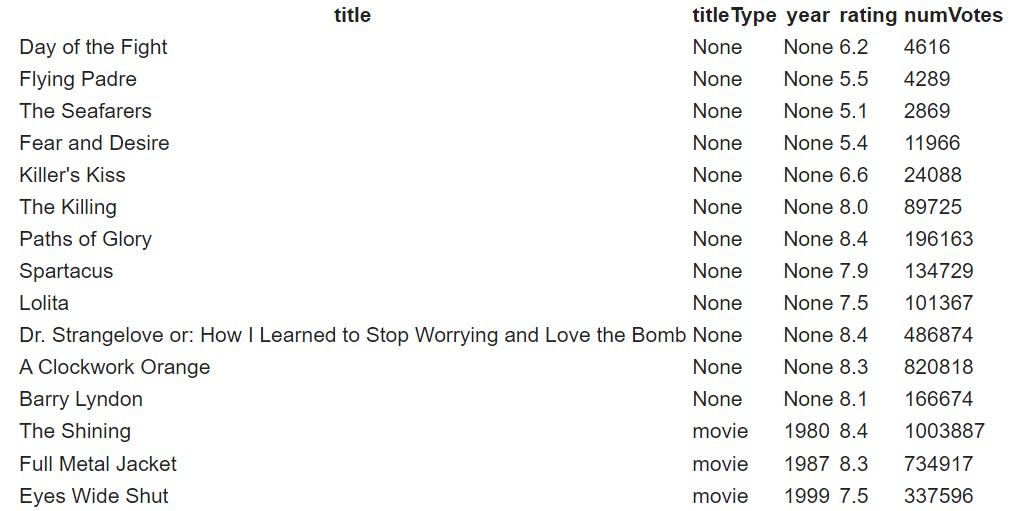
The resulting table had missing data as can be seen in the next image:
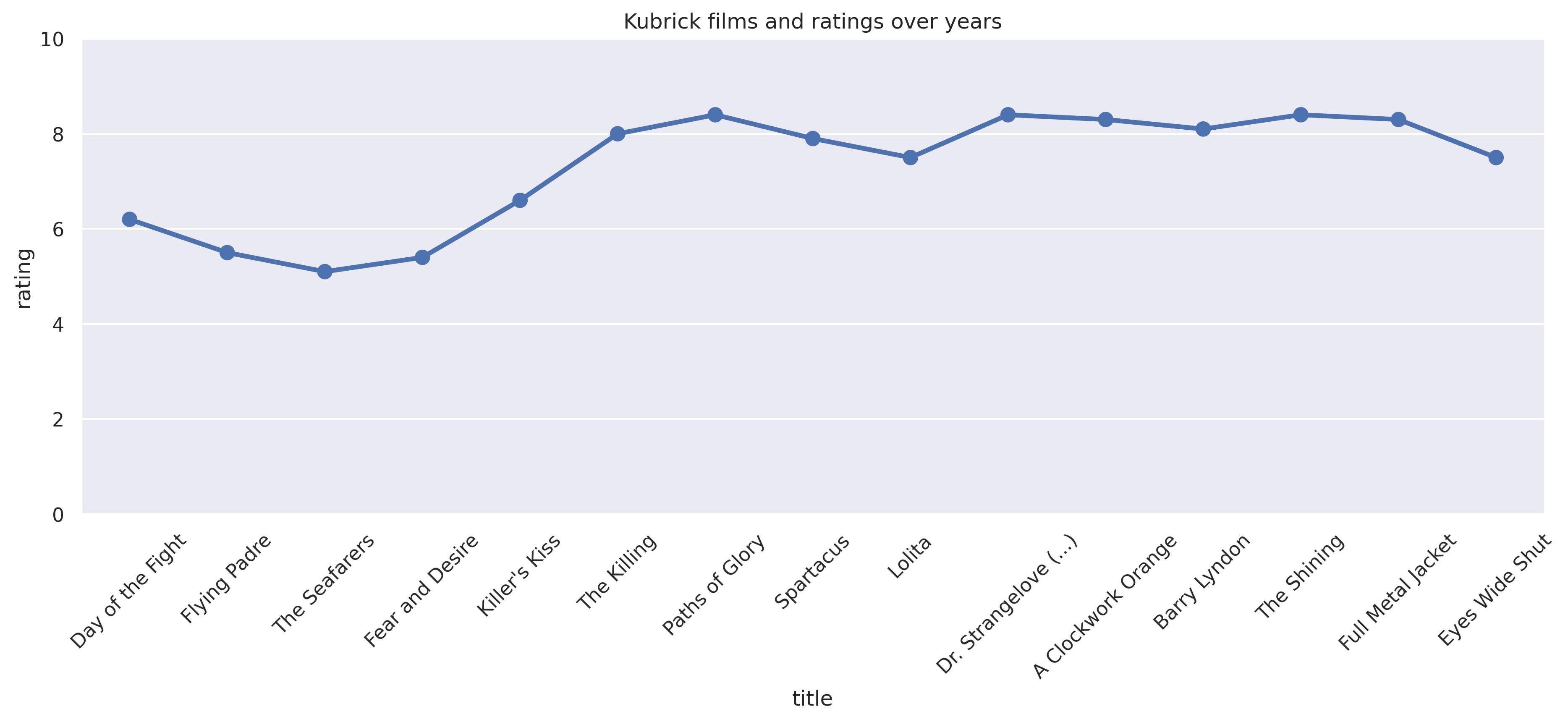
But at least it allowed me to make a simple plot showing the evolution of the director in terms of ratings and popularity (number of votes is used as a proxy for popularity)
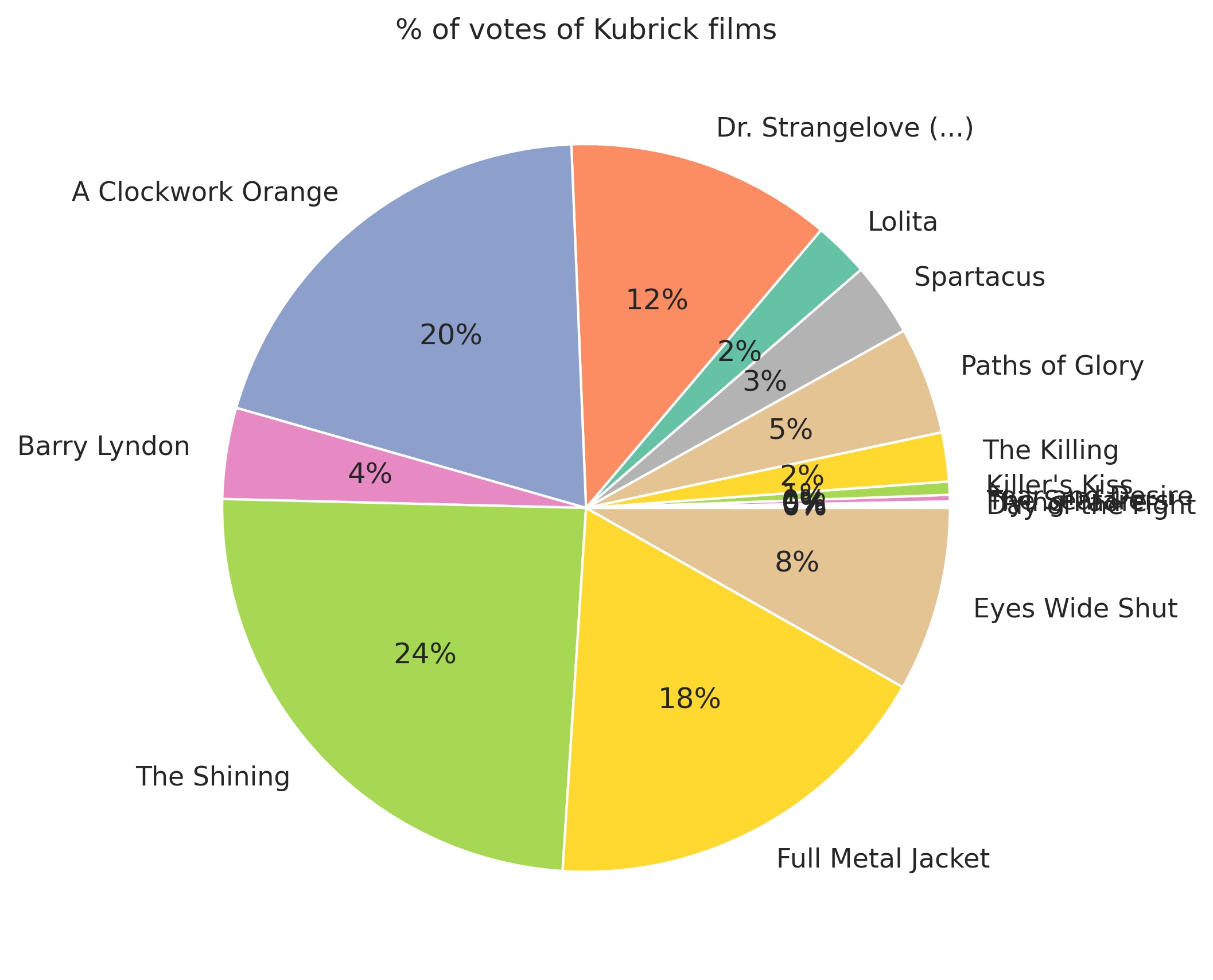
This is just a snippet. If you want to see more check my github repository here.