NLP with distrowatch reviews. Part II: Sentiment classification
Description
Some time ago, I contemplated transitioning to a Linux-based operating system, driven by my curiosity about the realm of free software and Linux culture. During my exploration, I stumbled upon the Distrowatch website (an invaluable resource offering information about numerous Linux distributions, including reviews). The organized and very structured layout of these reviews, coupled with the inclusion of numerical scores, sparked an idea within me. I envisioned gathering a substantial collection of these reviews—ranging from tens to potentially thousands—and subjecting them to analysis through Natural Language Processing (NLP). Eventually, this idea materialized into a tangible project, the outcome of which can be accessed here.
The project consists of three parts: Web scraping, supervised and unsupervised learning for sentiment analysis. We’ve already seen part I, let’s continue with sentiment analysis.
Problem definition
The idea is to predict the rating given by a user using only his/her review as input. However, this might not be as simple as it sounds, We need to clarify one basic assumption: we’re going to treat the prediction problem as a classification problem. If we had ratings with scores on a continuous scale with a greater range like 1-100, instead of 1-10, we could think about regression. Another thing to make clear is that, by default, we’re going to ignore the order present in ratings (i.e.: 10>8). In the notebook I explore one option to take order into account.
Basic data exploration
Usually, we’d first split the data but because there is no risk of data leakage (I think), we can take a look at the distribution of ratings in the full dataset:
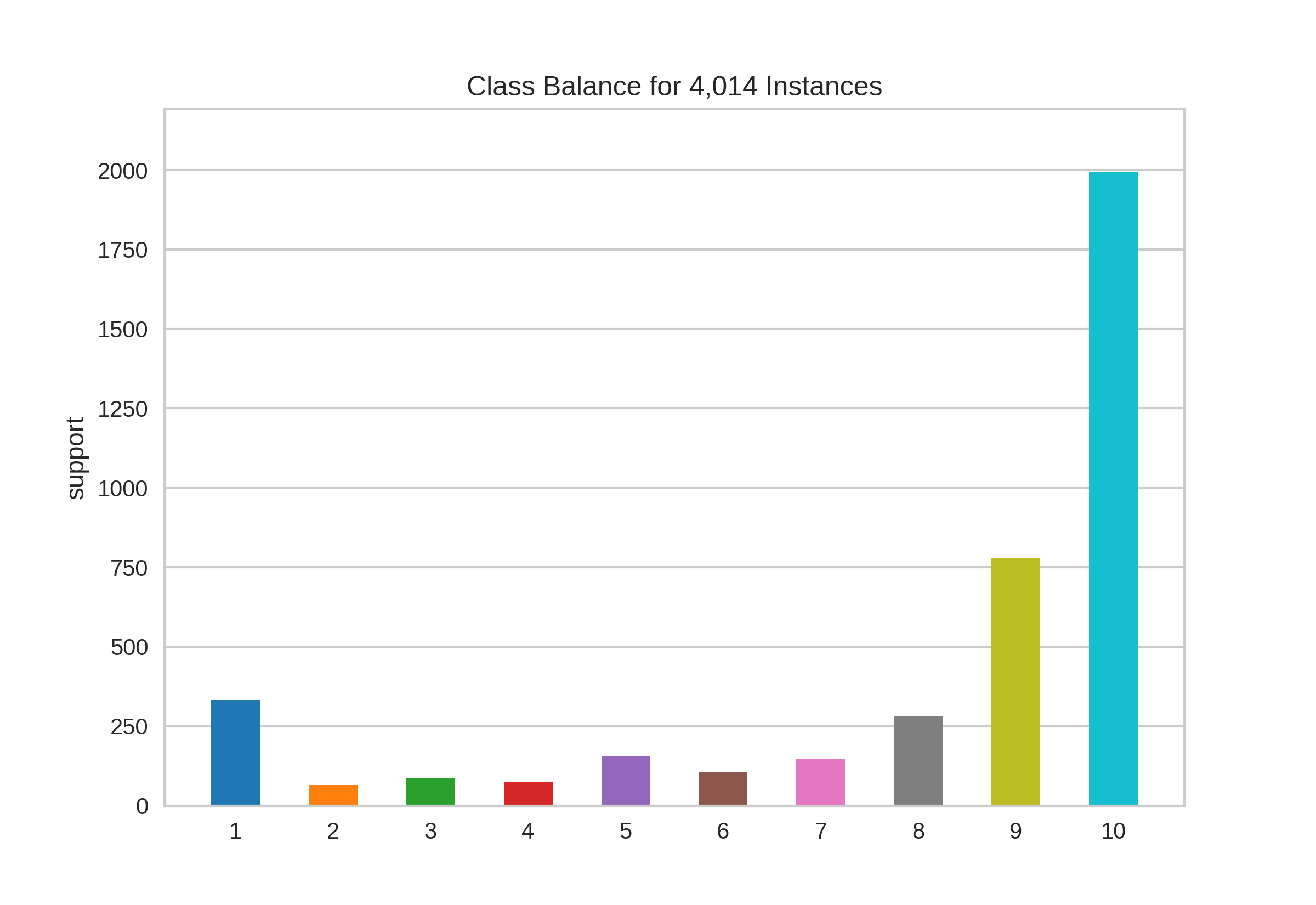
We’ve got 10 unique values and a very skewed distribution, most of the reviews we’ve collected are above 8. This translates into the problem of class imbalance.I don’t think I have enough expertise or data to treat this problem properly, so we’re going to make another assumption to simplify the problem. Given the relative prominence of extreme ratings, we could maybe assume scores are representing some underlying sentiment: negative, positive and maybe neutral. This means that there subsets of scores that belong to the same category (sentiment), but how can we group ratings? Here I’ll take a naïve approach and follow “common sense” (in part III I try other strategies). Here I show three possible options.
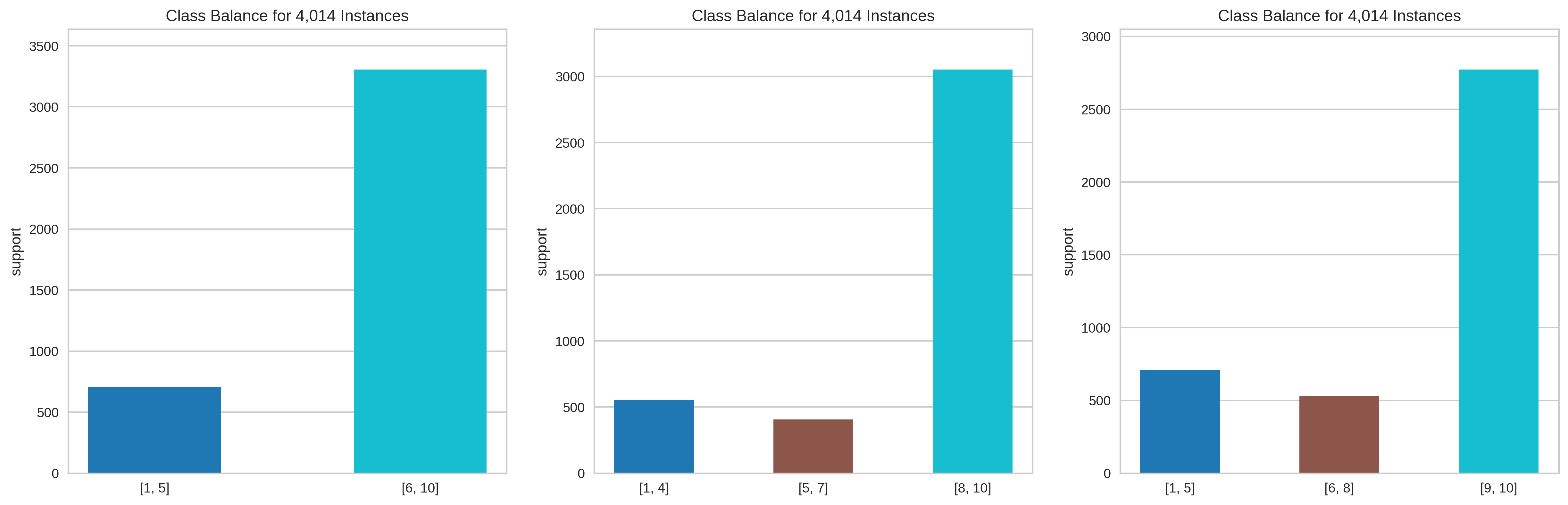
The first one seems reasonable and let us use binary classification algorithms (in the notebook I compare the performance using different target encoding)
Text pre-processing
Now we’re entering the realm of NLP. This is one of my first projects using NLP techniques, so I’ll keep it simple.
-
Tokenization:
- The tokens (“building blocks”) of the reviews are the words, more especifically unigrams and bigrams, that is, frustrating can be part of the vocabulary, but also the bigram very frustrating.
- Uppercase words are respected in some cases (not acronyms, for instance), because they can denote emphasis.
- Digits cannot be tokens (software versions, for example, are not deemed non-informative) except when presented in a format like 8/10, because explicit ratings can be very discriminative.
- Neither stemming nor lemmatization was applied. As I said, I wanted to keep it simple.
def preproc_tokenize(review):
text_rating = re.findall(r'\d\/10',review)
review_modif = re.sub(r'(\b[A-Z]{4,}\b)',r'upperc\1',review)
review_modif = re.sub(r'\d+\.?','',review_modif)
tokens = re.findall(r'(?u)\b\w\w+\b|[!|?]',review_modif.lower()) + text_rating
# stemmed_tokens = [SnowballStemmer('english').stem(w) for w in tokens]
return tokens
ex = 'xdistrox version 2.04 is a great distro! 8/10. It works in my OS VERY nicely. Why nobody is talking about it??'
print(ex)
print(preproc_tokenize(ex))
xdistrox version 2.04 is a great distro! 8/10. It works in my OS VERY nicely. Why nobody is talking about it??
['xdistrox', 'version', 'is', 'great', 'distro', '!', 'it', 'works', 'in', 'my', 'os', 'uppercvery', 'nicely', 'why', 'nobody', 'is', 'talking', 'about', 'it', '?', '?', '8/10']
-
Stop words
- Some specific words of this context are removed: OS, distro, version, the name of the distributions…The idea is to reduce the vocabulary size by discarding (supposedly) non-informative words.
- I keep some words like very or most, because they can be useful when expessing emotions.
to_keep = ['all','any','both','each','few','most','more','only','too','very'] # not
stop = [w for w in stopwords.words('english') if w not in to_keep]
extra_stop = ['OS','distro','LTS','version','Linux','USB','PC']
# names were obtained from distrowatch.com using web scraping, see notebook for part 1
with open("distro_names", "rb") as f:
distro_names = load(f)
stop.extend(extra_stop)
stop.extend(distro_names)
# stopwords need to be processed as any other token
stop_tokens = preproc_tokenize(' '.join(stop))
-
Vectorization
- Bag of Words: reviews are represented as vectors of counts with dimension equal to the total number of tokens in the dataset: the vocabulary size. The $i$-th entry of the vector for review $j$ stores the frequency of the $i$-th token of the vocabulary in the review $j$.
# Our Bag of Words vectorizer
bow_vectorizer = CountVectorizer(
lowercase=False, # transformation to lowercase is done in preproc_tokenize
tokenizer=preproc_tokenize, # custom preprocessing and tokenizing function
stop_words=stop_tokens, # custom set of stop words
token_pattern=None, # ignore, preproc_tokenize takes care
ngram_range=(1,2), # unigrams and bigrams
analyzer='word',
max_df=0.8,
min_df=20 # tokens have to appear at least in 20 documents -> this reduces the number of features drastically
)
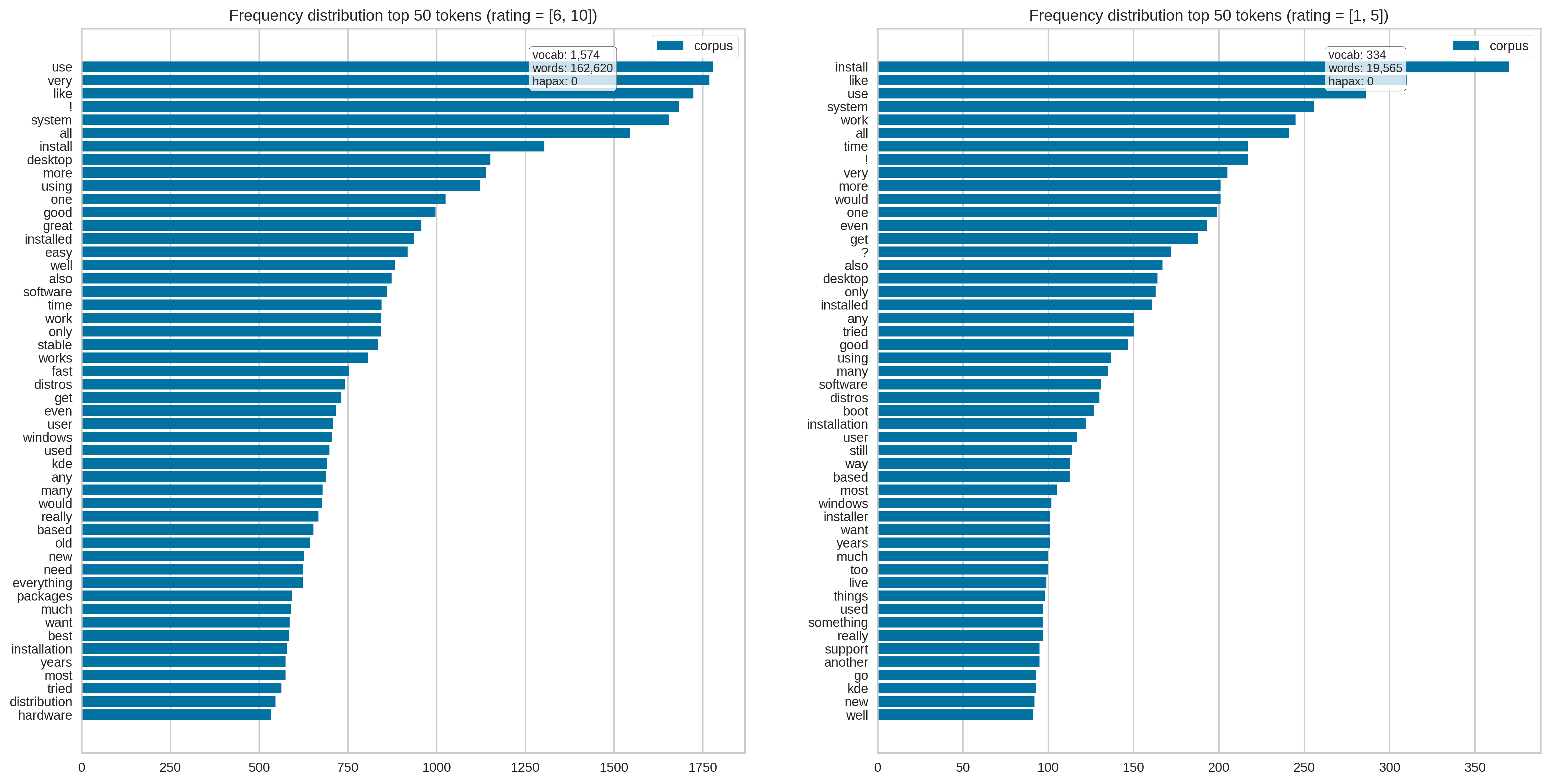
Our token distribution looks like this:
Model training and selection
For this section I haven’t done a careful search to find the best algorithm. I wanted to try the Naïve Bayes model because its simplicity and because it doesn’t require hyper-parameter tuning.
Classification rule: $\hat c=\underset{c\in K}{\operatorname{argmax}} P(c)\prod_{i=1}^{|V|} P(w_i|c)$
Where $c$ represents each of the $k$ classes, $w_i$ is the $i$-th token of the vocabulary set $V$, with size $|V|$
I compared the basic version, Multinomial Naïve Bayes Classifier (MNB), and the Complement Naïve Bayes Classifier (CNB), which is something like a improved version of MNB. I performed 5-cross-validation and used balanced accuracy for model selection, because it’s less misguiding in the presence of class imbalance than accuracy (or even AUC, as I’ve seen in other projects). With an average balanced accuracy of 0.813, CNB beat MNB, which obtained 0.801, so I chose the former as the final model.
However, those are cross-validation performance scores, and we need to see how well the final model performs on unseen data. The results for the test set are the following.
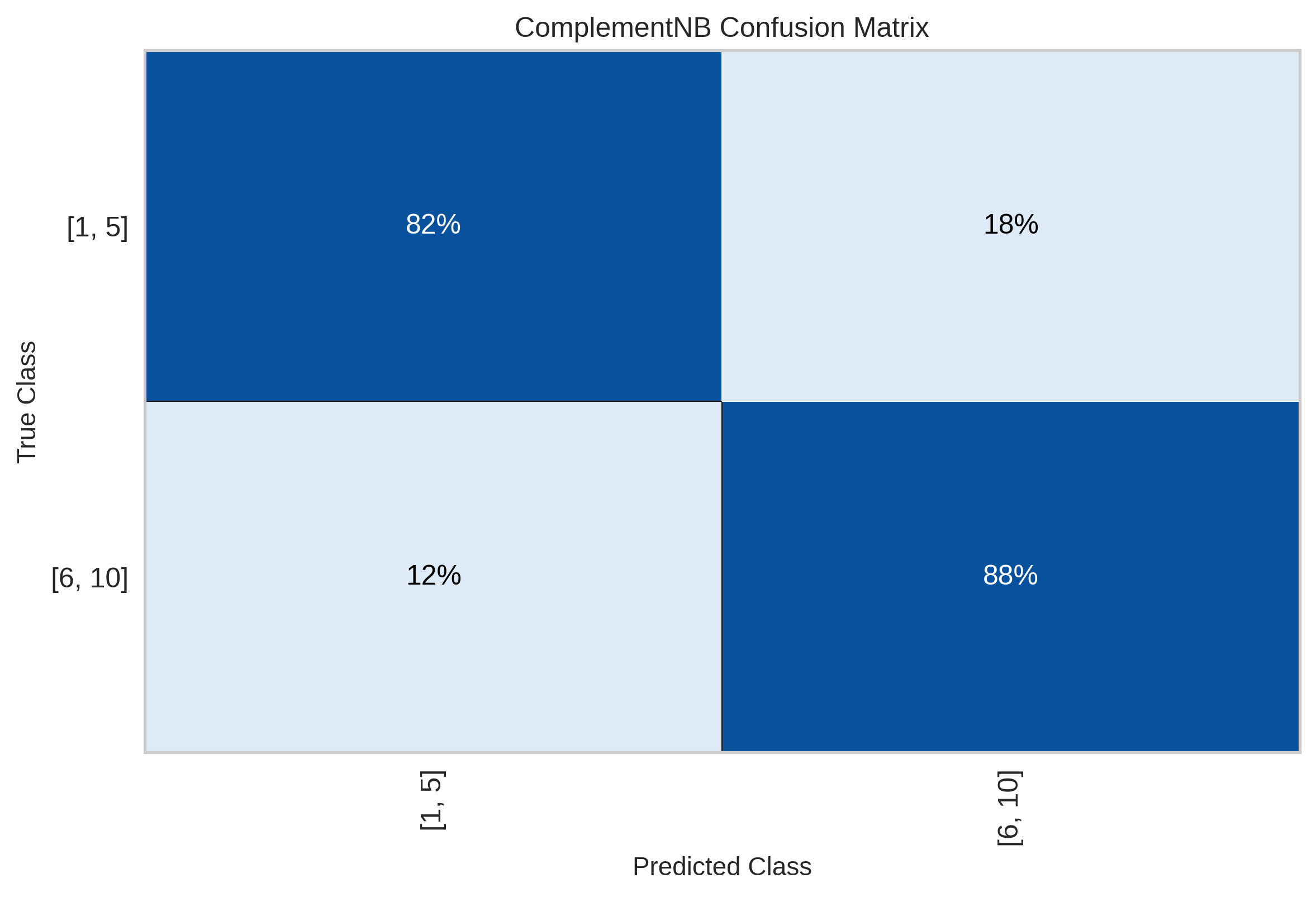
With global accuracy of 0.867 and balanced accuracy of 0.85.
Not bad, but far from excellent, a non-negiglible 18% of “negative” reviews are predicted as positive (maybe because of reviews on the border, those with rating of 5 or 6).
Which tokens are most relevant for classification?
The probability of a class is given by the review $d$ is
$P(c|d)=P(c)\prod_{i=1}^{|V_d|} P(w_i|c)$
where $w_i$ now represents the tokens present in review $d$ with vocabulary $V_d$, a subset of $V$
If we take the log:
$\log P(c|d)=\log P(c)+\sum_{i=1}^{|V_d|} \log P(w_i|c)$
It’s easier to see now that, as happens with linear regression, the bigger the value of $\log P(w_i|c)$, the greater importance the token $w_i$ has for predictions.
top_tokens = 15
neg_prob_sorted = final_model['clf'].feature_log_prob_[0, :].argsort()[::-1]
pos_prob_sorted = final_model['clf'].feature_log_prob_[1, :].argsort()[::-1]
print('negative reviews')
print(np.take(final_model['vectorizer'].get_feature_names_out(), neg_prob_sorted[:top_tokens]),'\n')
print('positive reviews')
print(np.take(final_model['vectorizer'].get_feature_names_out(), pos_prob_sorted[:top_tokens]))
negative reviews
['worst' 'sad' 'terrible' 'tried install' 'way too' 'shame' 'asks'
'asking' 'pass' 'previous versions' 'problematic' 'tries' 'failure'
'parts' 'get things']
positive reviews
['configurable' 'pleased' 'charm' 'well done' 'snapshots' 'upgraded'
'intel core' 'enjoying' 'unix' 'underrated' 'impressive' 'period'
'most stable' 'much easier' 'favourite']
Very revealing indeed. For example, when a user mentions problems with the installation process or mentions previous versions of the software, the review is probably going to be negative. On the other hand, comments about how configurable and stable is the linux distribution predict positive reviews.
If you want to know more about the project, check the part I and III. All the code can be found here.