NLP with distrowatch reviews. Part I: Web scraping
Description
Some time ago, I contemplated transitioning to a Linux-based operating system, driven by my curiosity about the realm of free software and Linux culture. During my exploration, I stumbled upon the Distrowatch website (an invaluable resource offering information about numerous Linux distributions, including reviews). The organized and very structured layout of these reviews, coupled with the inclusion of numerical scores, sparked an idea within me. I envisioned gathering a substantial collection of these reviews—ranging from tens to potentially thousands—and subjecting them to analysis through Natural Language Processing (NLP). Eventually, this idea materialized into a tangible project, the outcome of which can be accessed here.
The project consists of three parts: Web scraping, supervised and unsupervised learning for sentiment analysis. Let’s start with web scraping and data collection.
Inspecting the website
If we go to this site https://distrowatch.com/dwres.php?resource=ratings&distro={distro_of_choice}, we’ll see reviews like this one:
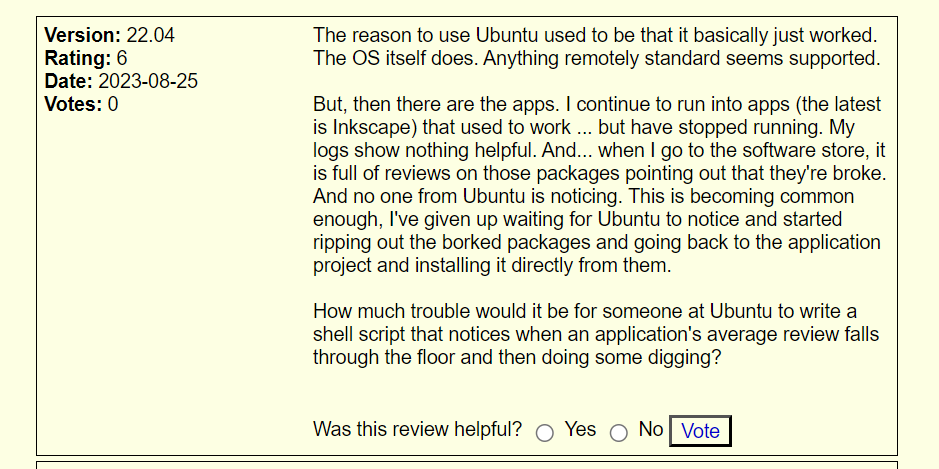
Just by seeing it, one has the feeling that the underlying html is going to be clearly structured and that is going to be relatively easy to access all of its parts. This is in fact what we see when we inspect elements:
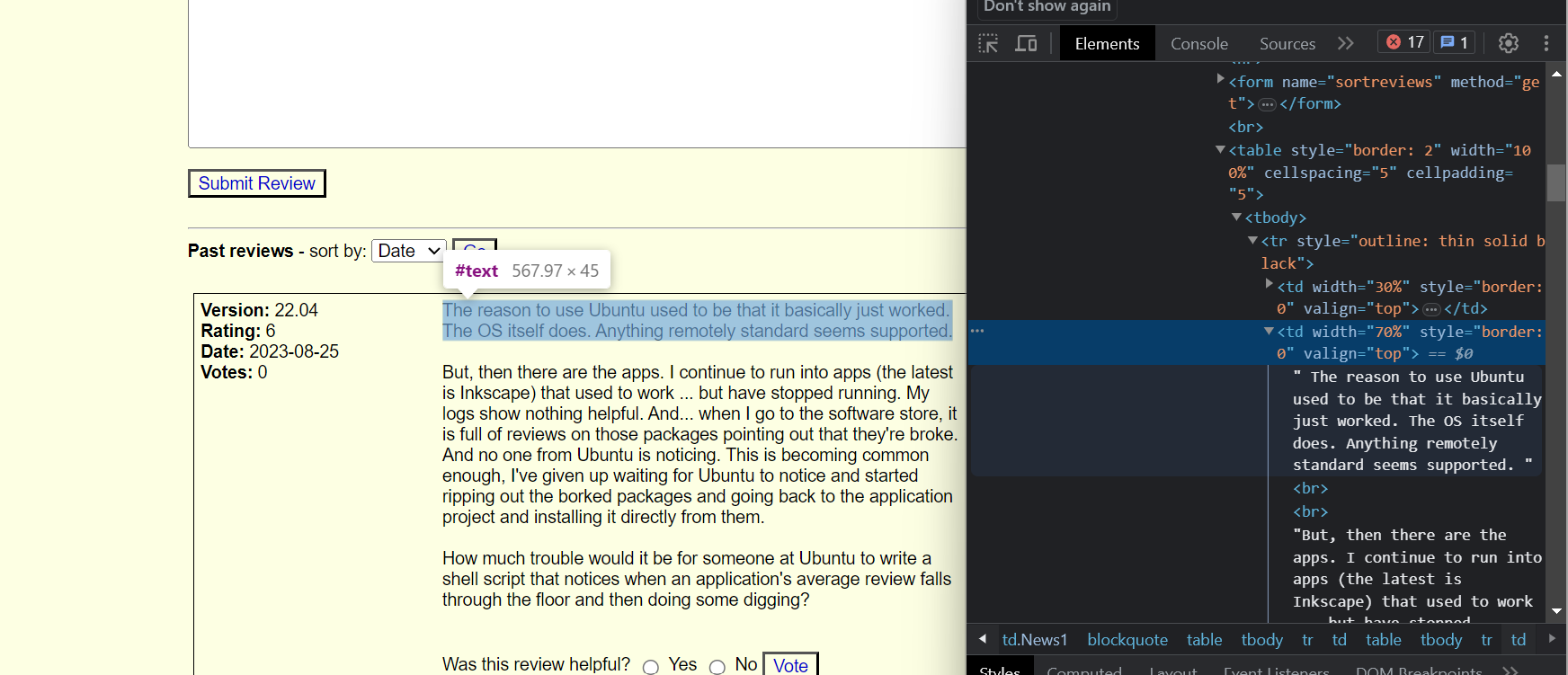
The code I used to extract each part is relatively simple, although, to be honest, I needed quite some time to get it because I’m not at all expert in web scraping.
total_reviews = sel.xpath('//td[@class = "News1"]//table[1]//td[2]/b[2]/text()').extract()
avg_rating = sel.xpath('//td[@class = "News1"]//table[1]//td[2]/div/text()').extract()
project = sel.xpath('//td[@class = "News1"]//table[2]//tr/td[1]/text()[3]').extract()
version = sel.xpath('//td[@class = "News1"]//table[2]//tr/td[1]/text()[4]').extract()
rating = sel.xpath('//td[@class = "News1"]//table[2]//tr/td[1]/text()[5]').extract()
date_review = sel.xpath('//td[@class = "News1"]//table[2]//tr/td[1]/text()[6]').extract()
votes = sel.xpath('//td[@class = "News1"]//table[2]//tr/td[1]/text()[7]').extract()
reviews = sel.xpath('//td[@class = "News1"]//table[2]//tr/td[2]/text()').extract()
There was a little problem, however. Notice the space between paragraphs in the hmtl from picture above? That was inconvenient because in the extracted reviews, different paragraphs were separated by /r, but different reviews are separated by \n. The subparts of the review (paragraphs) had to be joined together. Also, there was another \n character at the beggining of the next review. In order to split the reviews correctly I firstly “glued” all reviews and then used the pattern ‘\n\n’ to separate texts.
# the first reviews before processing
['\nUbuntu was the first distribution I used on Linux. Then I was a distrohopper for 4 years and learned everything about Debian/Ubuntu, Arch, Gentoo, Opensuse and other alternatives like Void, Slakware, etc.\r',
"I always come back to Ubuntu. I don't like snaps or the continuous error in the snap-store, but I feel that it is the most stable, modern and efficient distro.\r",
"When I want to learn about Linux, I use other distributions, but when I want to work with Linux, I always go back to Ubuntu. I use flatpak because I like it better, nobody prevents it even if you don't have flatpak pre-installed.\r",
"Oh! and Ubuntu is the only distro I've installed on all types of hardware (old imac, new hardware, old hardware) and it always works. It just all works.\r",
'\r',
'\n',
'\nI have used Ubuntu Linux for years, and I have had good experiences with it most time.\r',
'\r',
"Firstly, it's user friendly. For someone switching from Windows to Linux, Ubuntu is a good start, not with a deep learning curve.\r",
"Secondly, it's supported by many popular software: alternative web browsers, VPN client tools, RDP tools, software development tools, etc.\r"]
reviews = ''.join(reviews).split('\n\n')
assert len(reviews) == len(rating) # to maje sure now we have the correct number of reviews
And that was pretty much all. I also retrieved the names of all distributions from other page of the web and faced other problems (limited number of reviews that could be accessed), but the heavy part was that.
Dataset creation
To create a dataset for posterior analysis I choose a simple method. I basically iterated over all the distros available and created a dataframe for each one with their information. Then I just concatenated all the dataframes. Each dataframe was defined as:
df_distro = pd.DataFrame({'date':date_review,
'project':project,
'version':version,
'rating':rating,
'votes':votes,
'review':reviews})
In the final df I made some modifications to avoid problems later and I saved it.
df = (
df.assign(date=pd.to_datetime(df['date']),
votes=pd.to_numeric(df['votes']),
rating=pd.to_numeric(df['rating']))
.reset_index(drop=True)
)
df.to_csv('distrowatch.csv')
That’s how a review looked:

If you want to know more about the project, check the part II and III. All the code can be found here.